Roll Your Own
Charting Your Success
This week we’re going to cover some generic programming topics in addition to some specific AppleScript syntax. I had mentioned last month that I was planning to delve further into the try…on error…end try block this time, but the topic of algorithms and flowcharts is so large that we’ll leave try blocks for next time.
Algorithms
Building complex software is no easy task. There are so many things to think about and keep straight. Over the decades, programmers have come up with tools to help them through the process. One of these tools is the algorithm.
An algorithm is simply a defined set of steps that accomplish a goal. My good old DK Illustrated Oxford Dictionary describes it as “a process or set of rules used for calculation or problem-solving, esp. with a computer.” For instance, if the goal is to reach a friend’s home, the algorithm is going to be the directions that he gives you. A common example to introduce students to algorithms is describing a system one might use for going through the mail.
Step 1: Get the mail from the mailbox.
Step 2: Go to your desk.
Step 3: Take the piece of mail on the top of the pile.
Step 4: If the mail you have is a bill, file it in “To Be Paid.”
Step 5: If the mail is a letter, read it. If not, go to step 7.
Step 6: Write a reply to the sender.
Step 7: If the mail is junk mail, throw it away.
Step 8: If the mail is a magazine, place it in the magazine rack.
Step 9: If there is more mail in the pile, take the next one and go to Step 4.
Step 10: All Done!
Obviously this algorithm doesn’t cover all of the possibilities, but you get the idea. By giving these steps to someone else, they would be able to duplicate the actions needed to sort through the day’s mail.
Algorithms are actually more abstract than this. The above list of steps is one way to express the algorithm for sorting through the mail.
When beginning to write software, the first thing you need to ask yourself is, “What will this software accomplish?” That is your goal. Now that you have the goal in mind, how is it going to be accomplished? Remember, computers are really stupid and have no intelligence whatsoever. When defining what the steps are to solve a software problem, the steps have to be precise and detailed. Think through the problem slowly, making sure that you haven’t left out some obvious step. For instance, in the above algorithm, what happens if there is no mail in the mailbox? The algorithm doesn’t cover that possibility. Or what if the person reading the algorithm doesn’t have a desk? In such cases the algorithm breaks.
This is one of the sources of bugs in systems: not thinking the problem through enough for the computer to understand. Most of the time the first algorithm that you create for a problem will not be complete, and will need to be refined as you begin testing your software. If you’ve been working with the sample program that has been featured for the last few columns, perhaps you caught the early trouble with entering text into the displayed dialog box instead of a number. Our original program didn’t handle this eventuality very well, although the refined version we wrote last month does a better job.
While an algorithm does eventually need to be very detailed for it to be of true assistance, you don’t need to worry about all the details at once. Our mail sorting algorithm doesn’t cover the details of filing a bill in “To Be Paid,” but we can refine our algorithm to cover that later.
Let’s take a software problem and translate the solution to it into an algorithm. We will express this algorithm as “pseudocode.” Pseudocode expresses the algorithm with sentences that can be easily translated into computer language code. My background is in mathematics, so I hope those of you who hate math will forgive the problem I select, but we’re going to build an algorithm that determines if a given number is a prime number or not. Non-prime numbers are also known as composite numbers.
A prime number is a positive whole number that is evenly divisible by exactly two numbers: itself and 1. Another way to put it is that prime numbers have only two factors. Given this definition, the first 4 prime numbers are 2, 3, 5, and 7. 1 is not a prime number because it is evenly divisible by only one number, itself. 4 is divisible by 1, 2, and 4, so it isn’t a prime number either, and 6 is excluded because it is divisible by 1, 2, 3 and 6. In fact, with the exception of 2, no even numbers are prime because they will all be evenly divisible by 1, 2 and themselves, which is at least three factors.
OK, so now that we know what a prime number is, let’s try building an algorithm that determines if a number is prime.
First of all, we know that if the number is negative, then it isn’t prime.
Step 1: If the number is negative, then it isn’t prime.
What if the number is 0. 0 isn’t prime because it’s evenly divisible by everything (0 divided by anything is 0).
Step 2: If the number is 0, then it isn’t prime.
We already covered the number 1, which isn’t prime.
Step 3: If the number is 1, then it isn’t prime.
Normally, if the number is even, it isn’t prime, but 2 is a special case, so we’ll cover it by itself.
Step 4: If the number is 2, then it is prime.
So here’s what we have so far:
Step 1: If the number is negative, then it isn’t prime.
Step 2: If the number is 0, then it isn’t prime.
Step 3: If the number is 1, then it isn’t prime.
Step 4: if the number is 2, then it is prime.
Hold on a second. We can refine our algorithm right away. The first three steps all determine if the number isn’t a prime number in special cases, but all three cases can be covered with one test!
Step 1: If the number is less than or equal to 1, then it isn’t prime. All Done! Otherwise, go to step 2.
Step 2: If the number is 2, then it is prime. All Done!
OK, we’ve finished with the special cases. Now lets get more general. For all the other numbers, we need to test them somehow. The way we test is to begin counting from 2 up to the number. If we ever reach a number while counting where the number we are testing divided by the number we are counting with is a whole number, then the number we are testing isn’t prime, since if we had divided the test number by the counting number and gotten a whole number result, the test number would be a third factor. If we count all the way to the prime number and we never see a whole number quotient, then the number is prime.
Step 3: Begin counting at 2. Call the number you are counting with X and the number you are testing Y.
Step 4: If Y divided by X is a whole number, then X is not prime.
Step 5: Increment X by 1.
Step 6: If X is equal to 1 less than Y, the number isn’t prime.
Ah! We’re using variables! Remember variables from our earlier column? Actually, we could use another variable, and let’s give our variables some meaningful names. And let’s include the step where we actually get the number from somebody. Also, let’s include some more flow in our algorithm (remember flow from last column?). After all, if we figure out if the number is prime in step 4 then we don’t have to do step 5, do we?
Step 1: Get a number from the user and store it in the variable theNumber.
Step 2: Set a variable called isPrime to false.
Step 3: If theNumber is less than or equal to 1, go to step 10.
Step 4: If theNumber is equal to 2, set isPrime to true and go to step 10.
Step 5: Set a variable called testDivider to 2.
Step 6: If theNumber divided by testDivider is a whole number, go to step 10.
Step 7: Increment testDivider by 1.
Step 8: If testDivider is 1 less than theNumber, set isPrime to true. Go to step 10.
Step 9: Go to step 6.
Step 10: Tell the user the value of isPrime.
Let’s test out the algorithm now and see how it does. We know that 7 is a prime number. Does the algorithm give this result? Well, step 1 stores 7 in theNumber. Step 2 stores false in isPrime. Step 3 checks if the number is less than or equal to 1, which it isn’t, so we go on to step 4, which tests if the number is equal to 2. Also not true, so we go to step 5. We store 2 in testDivider. In step 6 we see if 7 / 2 is a whole number. 7 / 2 is 3.5, which is not a whole number, so we go on to step 7. After incrementing testDivider by 1, it is equal to 3. 3 is not equal to 7 - 1, so we go to step 6 again. 7 / 3 is 2.333, which isn’t a whole number, so we increment testDivider again and get 4. 7 / 4 is 1.75, also not a whole number, so we increment again and get 5. 7 / 5 equals 1.4, again, not a whole number. Then we try 7 / 6, which is 1.167, still not a whole number. This time, however, testDivider is equal to one less than theNumber, so we go to step 10. The variable isPrime never changed from the false we originally set it to, so we tell the user that 7 is prime.
It worked! But it sure took a lot of counting. Once you have an algorithm that works successfully, you can begin to think about how it can be improved. Often, an easy area for improvement is speed. Can we make the algorithm faster? Let’s think about it for a minute.
If a number isn’t prime, how soon can we guarantee that we will reach a factor? Factors are always going to come in pairs. Take the number 24, for instance. Its factors are 2, 3, 4, 6, 8, and 12. Each of those numbers can be paired with another of the numbers. 2 times 12, 3 times 8 and 4 times 6 are all equal to 24. Where does the pairing break?
It turns out that the square root of 24 is about 4.8, and half of the factors are less than that and half of them are greater than that. So if we increment the testDivider and it’s greater than the square root of theNumber and we haven’t yet found a factor, we know the number is prime. That means that we can break out of our testing earlier than we thought. Here’s the revised algorithm:
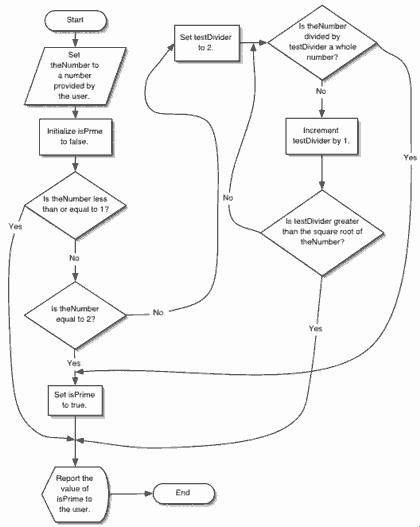
Step 1: Get a number from the user and call it store it in the variable theNumber.
Step 2: Set a variable called isPrime to false.
Step 3: If theNumber is less than or equal to 1, go to step 10.
Step 4: If theNumber is equal to 2, set isPrime to true and go to step 10.
Step 5: Set a variable called testDivider to 2.
Step 6: If theNumber divided by testDivider is a whole number, set isPrime to true and go to step 10.
Step 7: Increment testDivider by 1.
Step 8: If testDivider is greater than the square root of theNumber, set isPrime to true. Go to step 10.
Step 9: Go to step 6.
Step 10: Tell the user the value of isPrime.
Notice how easily this pseudocode can be translated into AppleScript syntax. By thinking things through before we actually begin to write any code, we have made the code writing very easy. This is how programming works. After defining a problem and creating a solution in the form of an algorithm, all that’s left is to translate the algorithm into code the computer understands. We’ll wait to actually do that translation until we cover the next programming tool, flowcharts.
Flowcharts
Another useful tool for programmers is the flowchart. The flowchart is closely related to the pseudocode. In fact, they provide the same information, but in different forms. Whereas pseudocode is written down as the steps to perform, a flowchart shows how the steps fit together in a graphical format. Both express the algorithm in a human understandable format.
There are standard symbols that are used in flowcharts to signify different kinds of steps. The algorithm we’ve been working on has at least four different types of steps: input, output, processes, and decisions. Each of these type of steps has a different symbol in a flowchart. There are many other symbols that are standard for flowcharts, but these are the ones we’ll work with for now.
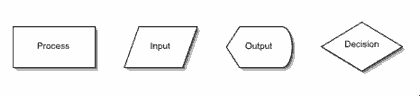
You don’t have to use these symbols, but they are helpful when reading the flowchart. Also, if you’re passing your flowchart on to others they’ll be able to read it more easily. Some of the symbols are ambiguous. For instance, what I’ve labeled as Input is sometimes also used for output, with a different symbol for manual input. In other words, the symbol I use for input is used for disk input or network input rather than user input. And the symbol I use for output is sometimes used only for output that is put on the screen, with different symbols for writing to disk. But most of the programs I write have the majority of their output to the screen, and the output symbol I have decided to use (being similar to an arrow) helps me visually see that this is what is happening.
Symbols in a flowchart are connected with arrows to indicate the flow of the program.
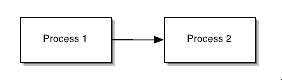
Here we see that Process 1 is followed by Process 2. Most symbols have two arrows connected to them, one coming in and another going out. However, the decision symbol is an exception to this rule. Like most other symbols, it has one arrow leading to it, but it had two arrows leading out, one for if the decision returns a “Yes” answer and another if the decision returns a “No.” Each of the arrows that leads out of a decision symbol is labeled with either “Yes” or “No.” When the arrow leading from a decision symbol meets another arrow in the flowchart, the flow of the program continues in the direction of the met arrow.
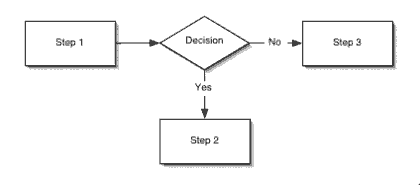
There is one special symbol that appears twice in every flowchart, the start/stop symbol. There will be one at the beginning of the flowchart and it should be labeled “Start” or “Begin” and another at the end of the flowchart labeled “End” or “Finish.” The flowchart always begins at the “Start” symbol and execution must always end up at the “End” symbol.
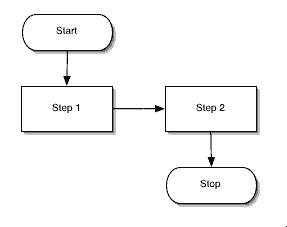
As you can see from the flowcharts that I’ve given as samples, the flow of the flowchart tends to move from top to bottom and left to right.
Flowcharts can be built with any drawing program such as AppleWorks (review) or Illustrator (review). You can even use the drawing tools included with Microsoft Word. However, there are a couple of programs that have been built specifically for building flowcharts. If you’re using Mac OS X, I can highly recommend OmniGraffle from The Omni Group. The Omni Group is well known for publishing beautiful software for Mac OS X. Available for Mac OS X or Classic is ConceptDraw from Computer Systems Odessa, which we published a review of last year. On the Mac Classic side, MacFlow from Mainstay is also available, which I used for years before migrating to OmniGraffle.
Now that we have the basic symbols needed to create flowcharts, let’s take a look at our prime number algorithm when it is translated into a flowchart.
Which to Use?
You’ve got two new tools on your belt now—pseudocode and flowcharts. Which one of them should you use when building software? It’s a matter of personal preference. Which do you find easier to understand? Which do you find easier to create? I use both of these tools, although my preference tends to lean toward flowcharts. Try them both out and see which you prefer. The point of these tools is not that you must use one or the other, but that you must think about your program before you actually begin to write code.
Since we’ve got the pseudocode set and we’ve got the flowchart to reference, let’s translate our two tools into AppleScript code. After all, this is a programming column. I suppose we should have some code in it this month.
-- Get a number from the user and store
-- the number in the variable theNumber.
set theNumber to text returned of ¬
(display dialog "Please enter a number to test:" ¬
default answer "" ¬
buttons {"OK"} default button 1)
-- Initialize isPrime to false.
set isPrime to false
-- If theNumber is less than or equal to 1,
-- we don't need to do anything
-- since isPrime is already set to false.
if theNumber is less than or equal to 1 then
-- Don't do anything here.
-- if theNumber is 2, change isPrime to true.
else if theNumber is equal to 2 then
set isPrime to true
-- If theNumber is greater than 2,
-- enter a loop that tests for factors.
else
-- Initialize testDivider to 2.
set testDivider to 2
-- Enter a repeating loop.
repeat
-- The following if tests whether
-- enter a loop that tests for the quotient
-- of theNumber and testDivider is a whole number.
if (theNumber / testDivider) = ¬
(round (theNumber / testDivider) rounding down) then
-- If it is, we can exit the loop.
exit repeat
else
-- Otherwise increment testDivider.
set testDivider to testDivider + 1
-- If after incrementing testDivider it is greater than the
-- square root of theNumber, we have a prime number.
if testDivider is greater than (sqrt (theNumber)) then
set isPrime to true
exit repeat
end if -- testdivider is greater than (sqrt(theNumber)) then
end if --(theNumber / testDivider) =
--(round (theNumber / testDivider)) then
end repeat
end if -- theNumber is less than or equal to 1 then
if isPrime then
display dialog theNumber & ¬
" is prime." buttons {"OK"} default button 1
else
display dialog theNumber & ¬
" is not prime." buttons {"OK"} default button 1
end if -- isPrime then
Reading through this program, you can see that it follows the flowchart and pseudocode pretty closely. But you may also notice that the program isn’t as compact as it might be. For instance, we have an if statement that doesn’t do anything if it’s true. The truth is that no matter how well you build your algorithm, the computer doesn’t always think in the ways the tool does. Although we can force the AppleScript language to follow the algorithm, we could probably create a more compact program by taking better advantage of the AppleScript language.
However, creating a working program was easy once we had the logic of solving the problem taken care of with our programming tools. From here we can modify the program as we like to make it more efficient for the language that we have decided to use, in this case, AppleScript.
One last item to note: the program code is another version of the algorithm. Just like the pseudocode and the flowchart, it expresses in human readable format the logic of the algorithm. If you gave any one of these versions of the algorithm to someone (and they understood the AppleScript language), that person could translate the algorithm to another language, such as C or REALbasic.
That’s it for this month. Join us again next time when we’ll cover some more AppleScript syntax in the form of try blocks and handlers, and how these AppleScript features relate to programming in general. As always, e-mail me with any questions or suggestions. Your comments are always welcome.
![]() Copyright © 2002 Charles Ross,
cross@atpm.com. Charles Ross is an independent programmer and author. He’s written articles for ISO FileMaker Magazine and is currently writing a book on creating applications with AppleScript.
Copyright © 2002 Charles Ross,
cross@atpm.com. Charles Ross is an independent programmer and author. He’s written articles for ISO FileMaker Magazine and is currently writing a book on creating applications with AppleScript.
Also in This Series
- Getting the List of It—Part 2 · July 2003
- Getting the List of It · June 2003
- The Object of Programming—Part 2 · March 2003
- The Object of Programming · February 2003
- How to Handle Anything · January 2003
- Try to Handle This · December 2002
- Charting Your Success · September 2002
- Go with the Flow · August 2002
- Variables and Data · June 2002
- The Ultimate Customization · May 2002
- Complete Archive
Reader Comments (3)
Your choice of a prime generator interests me, especially since primes are my hobby. :-) For instance, within the "non-predictable" non-pattern of primes, there exist subsets of predictability such as the mersienes. The sieve is simply a forward extensible recursive brute force trial-and-error procedure used by people who can't identify an algorithm. Mathematical proofs (algorithms) and formal logic both operate deductively, as does all good programming. A better algorithm would identify the domain of composites (generative) then compare the element to be tested into the domain (extractive). If it doesn't exist, then it's prime (negative logic--deductive.
The domain can be constructed by summing the power series of each integer beneath the square root of the boundary (volumetric rather than linear). Graphing each power series elicits some cool "real" data. The overall graph of progression of primes "appears" chaotic but, by doing the above graphs, one can easily see that, at each perfect square, a "correction" is introduced. Each correction is corrected at the perfect cube intercept, and so on. This is 100% predictable and it is additive at each intercept. Therefore, sigma the lot and, if x is not an element, then x is prime. Count the number of intercepts via integration and you can now say x is the Nth prime. Cool, eh?
Now try this: create a domain as above from the set infinity--x where x starts at zero and then becomes x+1 for each future iteration. Graph it. Hmmm. The same for 1, 2, 3, etc., only in reverse! This would tend to indicate that 1 is infinity, but the proof is temporarily beyond me and the above is only arithmetic. Does this have practical implications for programmers? I'll say! If the universe is both arithmetically and mathematically describable as a "one=infinity" grand circle, then it totally validates Hiesenburg. The algorithm used to determine code efficiency is a simple one-liner view of the uncertainty principle that should be in every programmer's toolbox to benchmark their code prior to release. The above observations tend to indicate that, in a complete universe, the large can be transposed with the small and vice versa. You just have to remember to also transpose your "direction" of time (in this case, the direction of propagation of your number line). If 1 can represent infinity and your decoder ring is programmed correctly, you can compress near infinity into next to nothing with no data loss! It gives a whole new meaning to the term, "Goedelize."
It can be applied to human language, genetics, infant education, and on and on. Don't believe me? I first worked it out about 20 years ago. I still have the original graphs somewhere. Try it for yourself. Get compressing!
Add A Comment